Speed Benchmarks
All numbers represent total TPS (Tokens per Second)
Single GPU
NVIDIA RTX 5090 32GB, CUDA 12.9
| Model | Unsloth NF4 | Unsloth BF16 | Surogate BF16 | Surogate FP8 | Surogate QoFP8 | Surogate FP4 | Surogate QoFP4 | Surogate QoNF4 |
|---|---|---|---|---|---|---|---|---|
| Qwen3 0.6B | 19,1k | 22,1k | 30,1k | 35,9k | 32.7k | 36.4k | 31,3k | 32,3k |
| Qwen3 1.7B | 12k | 12,6k | 14,0k | 18,8k | 17,4k | 20,7k | 17,0k | 17,6k |
| Qwen3 4B | 6k | 6.1k | 6,8k | 8,8k | 8,3k | 10,8k | 8,1k | 8,6k |
| Qwen3 8B | 3,4k | 3,5k | 3,8k | 5,4k | 5,0k | 6,9k | 4,9k | 5,0k |
| Qwen/Qwen3-30B-A3B | 0.016k | OOM | OOM | OOM | 0,5k | OOM | 0.5k | 0.5k |
Relative Speedup vs Unsloth NF4
| Model | BF16 | FP8 | QoFP8 | FP4 | QoFP4 | QoNF4 |
|---|---|---|---|---|---|---|
| Qwen3 0.6B | 1.57x | 1.88x | 1.71x | 1.91x | 1.64x | 1.69x |
| Qwen3 1.7B | 1.17x | 1.57x | 1.45x | 1.73x | 1.42x | 1.47x |
| Qwen3 4B | 1.13x | 1.47x | 1.38x | 1.80x | 1.35x | 1.43x |
| Qwen3 8B | 1.12x | 1.59x | 1.47x | 2.03x | 1.44x | 1.47x |
| Qwen/Qwen3-30B-A3B | - | - | 12.50x | - | 12.50x | 18.75x |
NVIDIA H100 80GB HBM3
| Model | Unsloth NF4 | Unsloth BF16 | Surogate BF16 | Surogate FP8 | Surogate QoFP8 | Surogate QoNF4 |
|---|---|---|---|---|---|---|
| Qwen3 0.6B | 18k | 21,3k | 53,9k | 51,2k | 16,5k | 16.6k |
| Qwen3 1.7B | 18k | 20,8k | 32,8k | 33,0k | 15,8k | 16,1k |
| Qwen3 4B | 11,5k | 12,4k | 15,9k | 17,0k | 11,2k | 11,0k |
| Qwen3 8B | 8,2k | 8,9k | 10,2k | 11,6k | 9,6k | 9,4k |
| Qwen3 14B | 5,2k | 5,6k | 6,0k | 7,2k | 6,5k | 6,1k |
| Qwen3 32B | 2,4k | 2,6k | TODO | TODO | 2,8k | TODO |
NVIDIA H200
| Model | Unsloth NF4 | Unsloth BF16 | Surogate BF16 | Surogate FP8 | Surogate QFP8 | Surogate QoNF4 |
|---|---|---|---|---|---|---|
| Qwen3 0.6B | 18,3k | 21,7k | TODO | TODO | TODO | TODO |
| Qwen3 1.7B | 18,3k | 21,4k | TODO | TODO | TODO | TODO |
| Qwen3 4B | 12,1k | 12,8k | TODO | TODO | TODO | TODO |
| Qwen3 8B | 8,4k | 9,1k | TODO | TODO | TODO | TODO |
| Qwen3 14B | TODO | TODO | TODO | TODO | TODO | TODO |
| Qwen3 32B | TODO | TODO | TODO | TODO | TODO | TODO |
NVIDIA B200
| Model | Unsloth NF4 | Unsloth BF16 | Surogate BF16 | Surogate FP8 | Surogate QFP8 | Surogate FP4 | Surogate QFP4 | Surogate QoNF4 |
|---|---|---|---|---|---|---|---|---|
| Qwen3 0.6B | 17k | 19,1k | TODO | TODO | TODO | TODO | TODO | TODO |
| Qwen3 1.7B | 16,7k | 20,3K | TODO | TODO | TODO | TODO | TODO | TODO |
| Qwen3 4B | 13,1k | 14,8K | TODO | TODO | TODO | TODO | TODO | TODO |
| Qwen3 8B | 11,3k | 12,4K | TODO | TODO | TODO | TODO | TODO | TODO |
| Qwen3 14B | TODO | 8,6k | TODO | TODO | TODO | TODO | TODO | TODO |
| Qwen3 32B | TODO | 4,2k | TODO | TODO | TODO | TODO | TODO | TODO |
NVIDIA B300 SXM6 AC
| Model | Unsloth NF4 | Unsloth BF16 | Surogate BF16 | Surogate FP8 | Surogate QFP8 | Surogate FP4 | Surogate QFP4 | Surogate QoNF4 |
|---|---|---|---|---|---|---|---|---|
| Qwen3 0.6B | TODO | TODO | TODO | TODO | TODO | TODO | TODO | TODO |
| Qwen3 1.7B | TODO | TODO | TODO | TODO | TODO | TODO | TODO | TODO |
| Qwen3 4B | TODO | TODO | TODO | TODO | TODO | TODO | TODO | TODO |
| Qwen3 8B | TODO | TODO | TODO | TODO | TODO | TODO | TODO | TODO |
| Qwen3 14B | TODO | TODO | TODO | TODO | TODO | TODO | TODO | TODO |
| Qwen3 32B | TODO | TODO | TODO | TODO | TODO | TODO | TODO | TODO |
Multi-GPU
4x NVIDIA RTX 5090 32GB, CUDA 12.9
| Model | Surogate BF16 | Surogate FP8 | Surogate QoFP8 | Surogate FP4 | Surogate QoFP4 | Surogate QoNF4 |
|---|---|---|---|---|---|---|
| Qwen3 0.6B | 111k | 131,3k | 120,5k | 136,2k | 118,5k | 120,0k |
| Qwen3 1.7B | 53,1k | 70,8k | 66,7k | 79,0k | 65k | 66,4k |
| Qwen3 4B | 25,8k | 34,0k | 32,2k | 41,3k | 31,4k | 32,0k |
| Qwen3 8B | 14,6k | 20,8k | 19,8k | 27,1k | 19,3k | 19,7k |
| Qwen/Qwen3-30B-A3B | OOM | OOM | 1.4k | OOM | 2.4k | 2.3k |
| openai/gpt-oss-20B | - | - | 3.8k | - | 2.2k | - |
Notes:
- Expert Parallelism: 4
gpt-oss-20Bis pre-quatized tomxfp4. This means only QLoRA training is possible.
Benchmark configuration
dataset = 10000 samples
max_seq_length=2048
per_device_train_batch_size = 2
gradient_accumulation_steps = 4
packing = True
lora rank = 16
lora_alpha = 32
lora_modules = ["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"]
Formulas used
Surogate install
curl -sSL https://surogate.ai/install.sh | bash
source .venv/bin/activate
Configurations used:
- Surogate BF16: ./benchmarks/benchmark_sft.sh "Qwen/Qwen3-0.6B" bf16
- Surogate FP8: ./benchmarks/benchmark_sft.sh "Qwen/Qwen3-0.6B" fp8
- Surogate QFP8: ./benchmarks/benchmark_sft.sh "Qwen/Qwen3-0.6B" qfp8
- Surogate FP4: ./benchmarks/benchmark_sft.sh "Qwen/Qwen3-0.6B" fp4
- Surogate QFP4: ./benchmarks/benchmark_sft.sh "Qwen/Qwen3-0.6B" qfp4
- Surogate NF4: ./benchmarks/benchmark_sft.sh "Qwen/Qwen3-0.6B" qbnb
Unsloth install
apt install -y python3-dev
uv venv --python=3.12
source .venv/bin/activate
uv pip install unsloth
Accuracy Benchmarks
We studied the impact of the recipes supported by Surogate using a custom version of the gsm8k dataset, specifically the ro_gsm8k dataset which is a Romanian translation of the original dataset.
Qwen/Qwen3-0.6B was chosen as a reference model. The measured accuracy of the original model on the ro_gsm8k dataset is close to 0, so this provides a good way to see how fine-tuning will teach the model this new dataset.
Summary table
| Precision / Config | accuracy | Stderr |
|---|---|---|
| BF16 | 0.2085 | 0.0095 |
| FP8 | 0.1888 | 0.0108 |
| FP4 | 0.1880 | 0.0108 |
| QBnB | 0.0940 | 0.0080 |
| QFP8 + fp8-hybrid | 0.1531 | 0.0099 |
| QFP8 + bf16 | 0.1698 | 0.0103 |
| QFP4 | 0.1600 | 0.0101 |
Loss charts
BF16
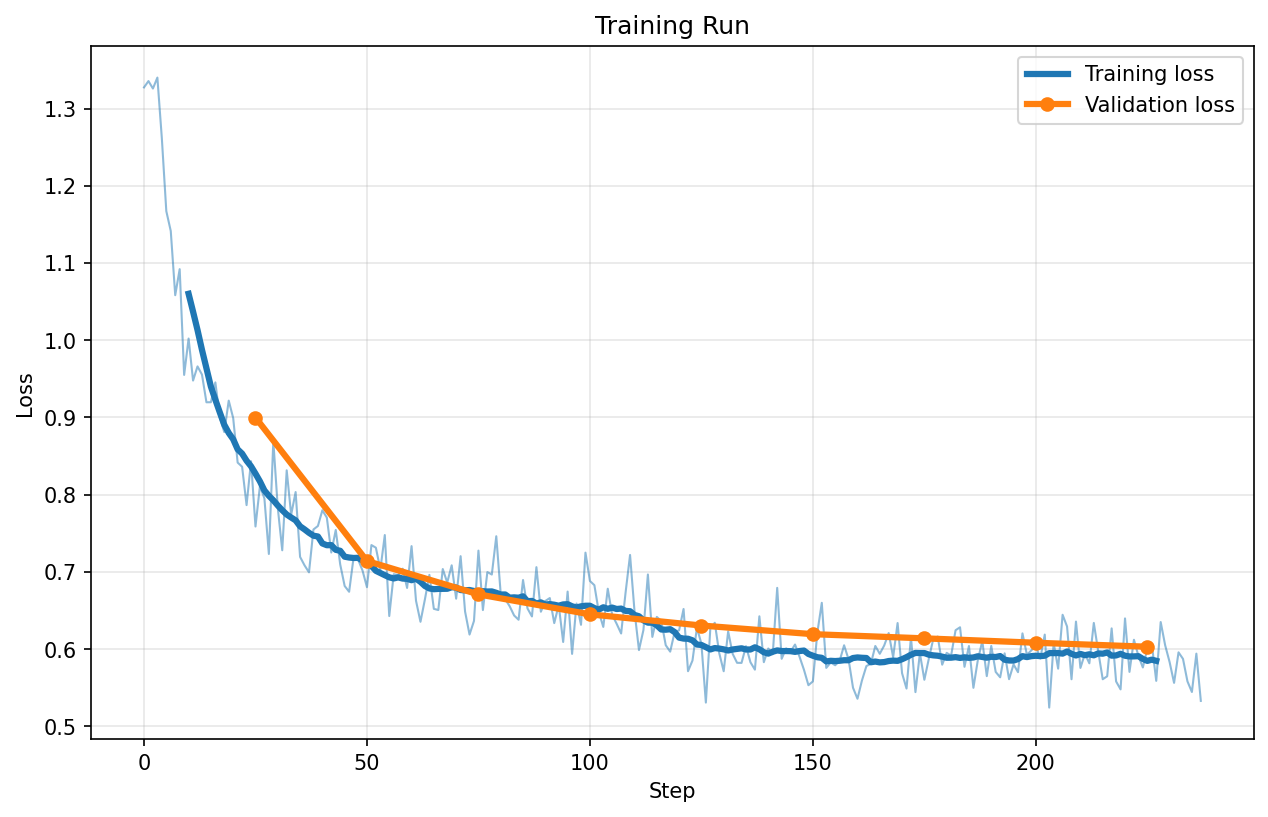
FP8
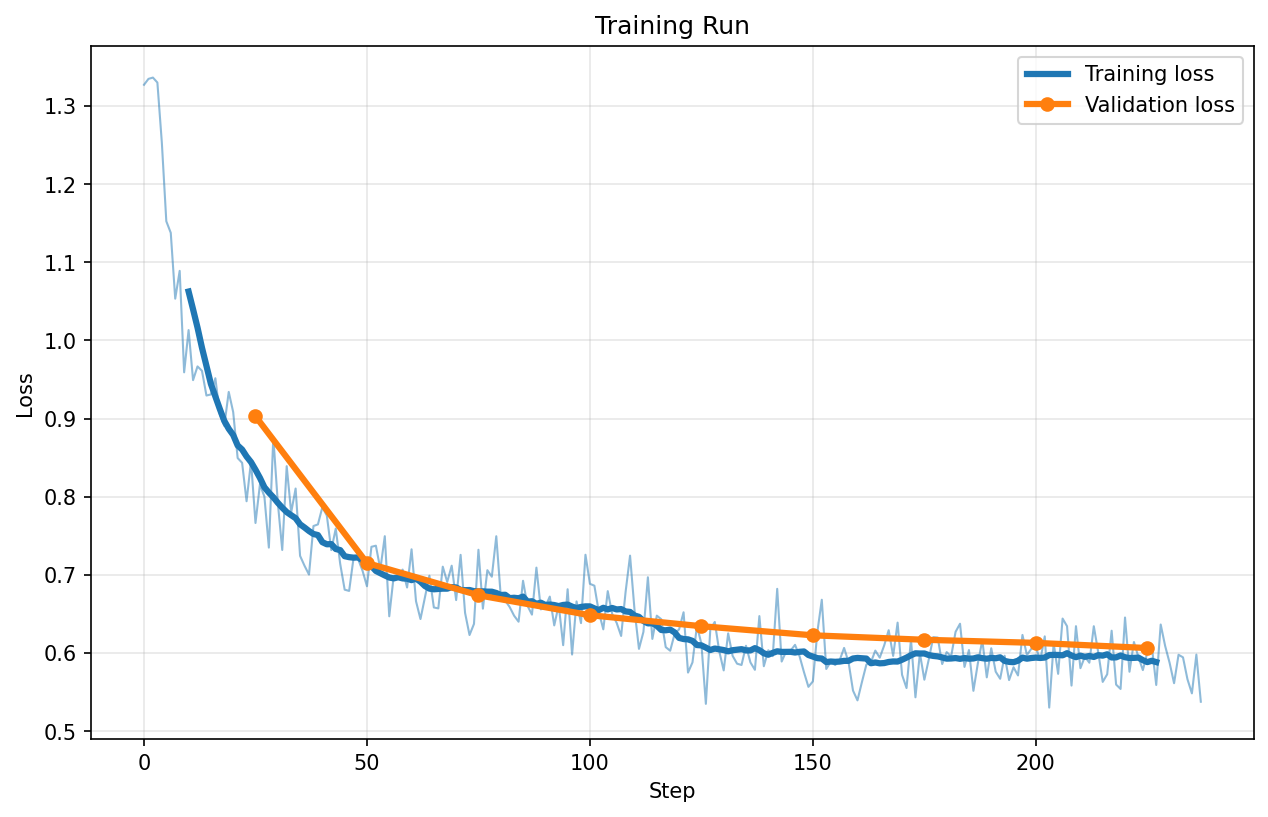
FP4
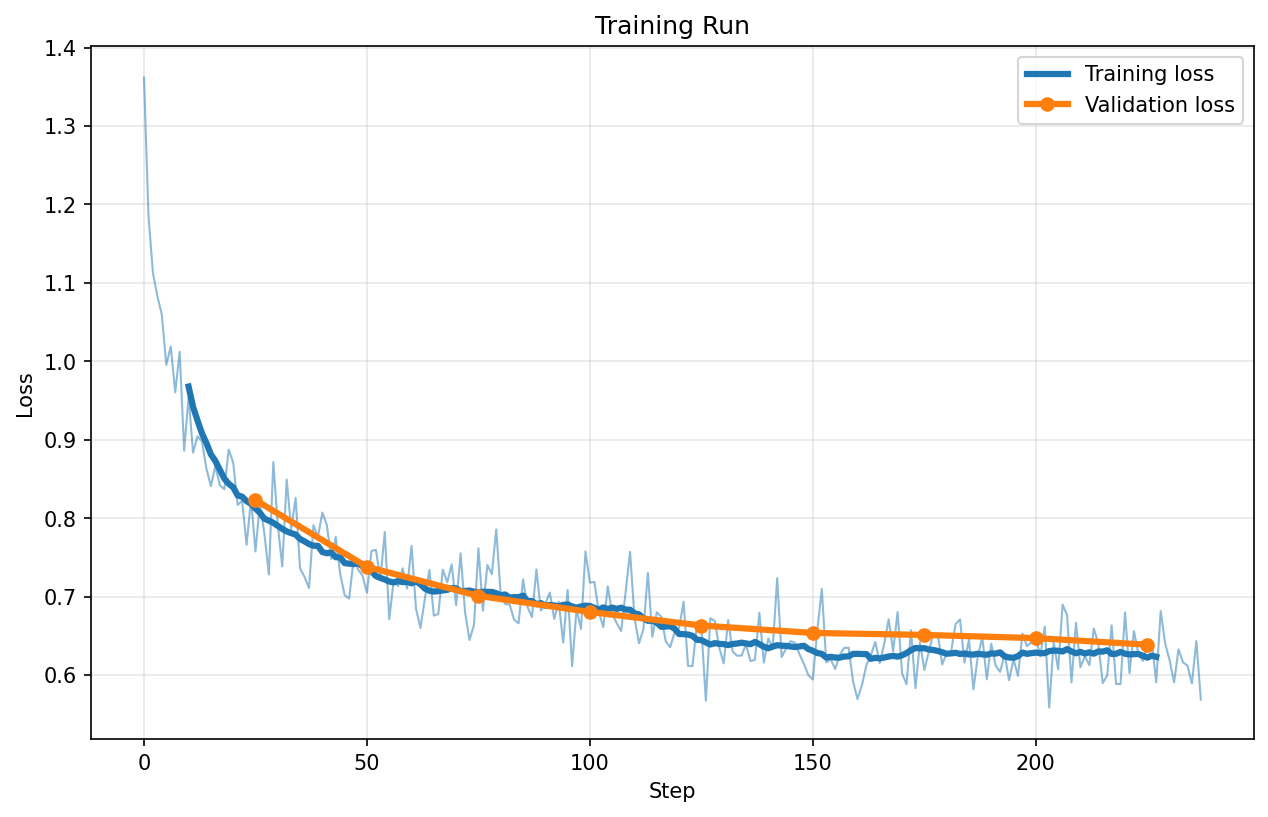
QBnB
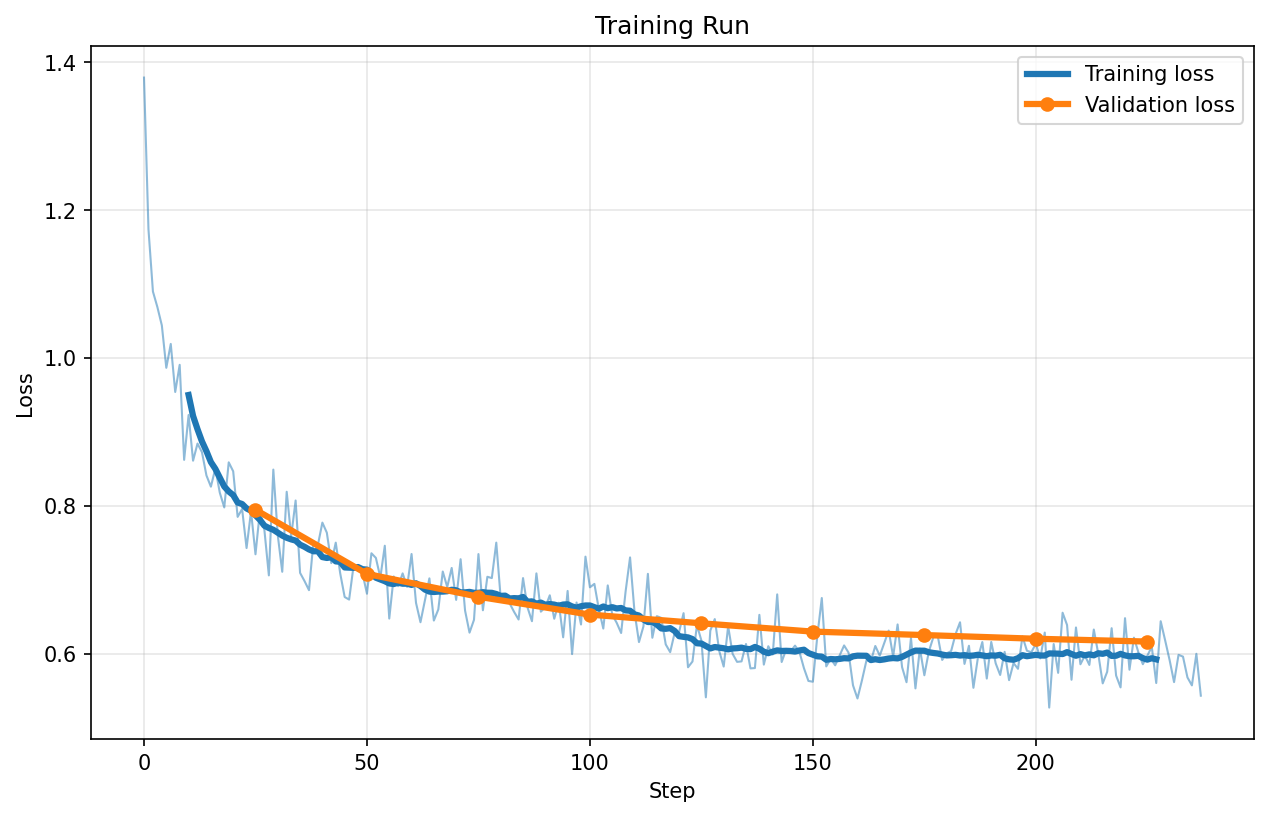
QFP8
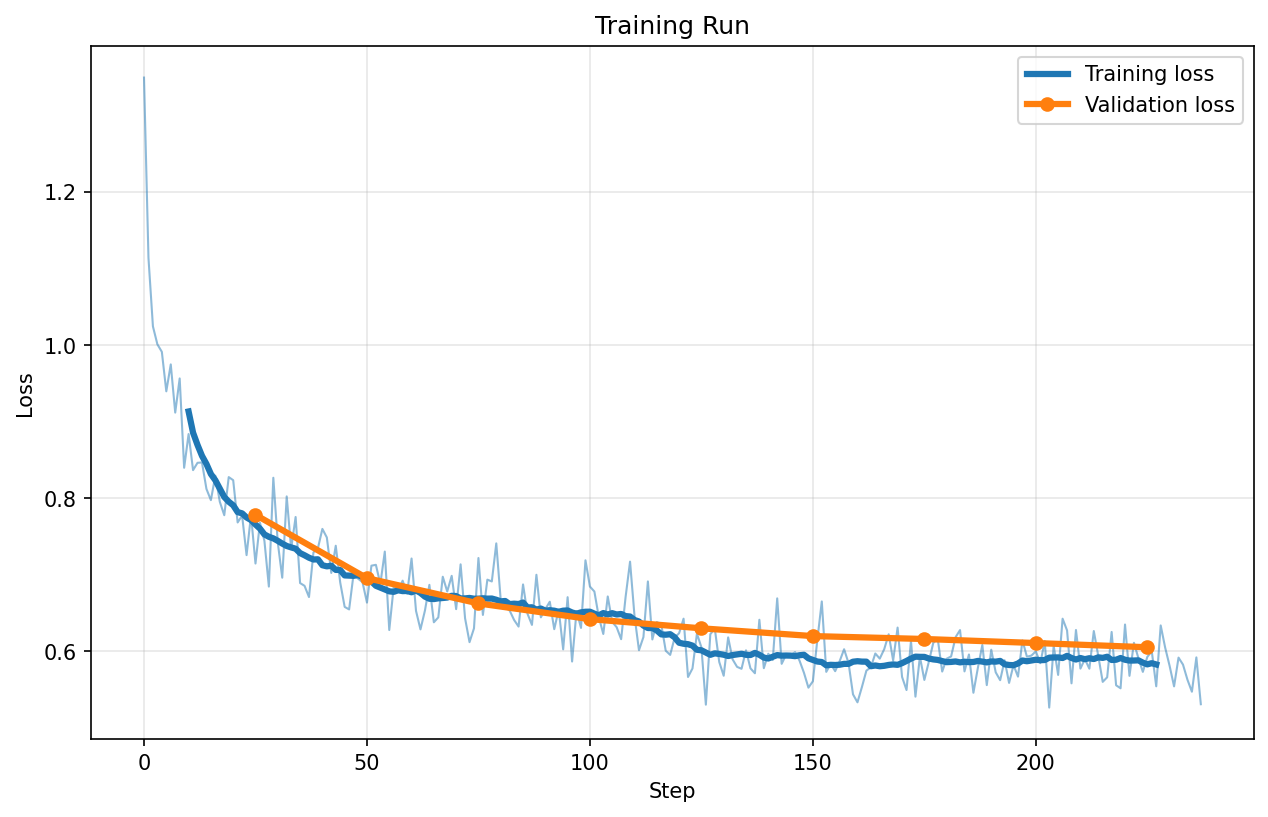
QFP4
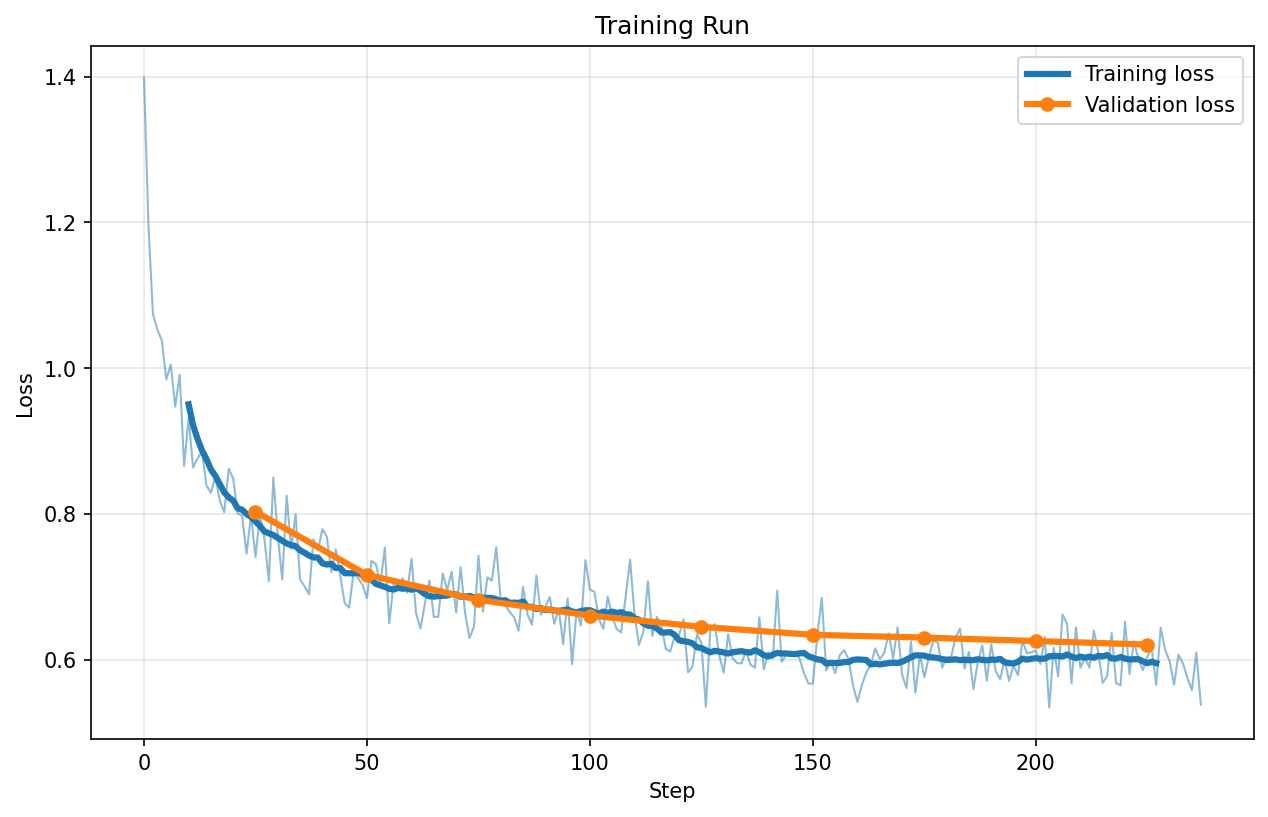
Config used:
per_device_train_batch_size: 2
gradient_accumulation_steps: 4
learning_rate: 2e-4
warmup_steps: 20
weight_decay: 0.001
lr_scheduler_type: linear
lora_dropout: 0
lora_rank: 16
lora_alpha: 32
lora_target_modules:
- q_proj
- k_proj
- v_proj
- o_proj
- gate_proj
- up_proj
- down_proj
Commands used:
VLLM_ALLOW_RUNTIME_LORA_UPDATING=True vllm serve Qwen/Qwen3-0.6B --max-model-len 2048 --max-lora-rank 64 --enable-lora --lora-modules adapter=/home/densemax2/work/flavius/surogate/output/benchmark_sft_bf16/adapter/ --port 8001
lm-eval --model local-completions --model_args model=adapter,base_url=http://localhost:8001/v1/completions,num_concurrent=50,max_retries=3,tokenized_requests=False,tokenizer=Qwen/Qwen3-0.6B --task gsm8k --num_fewshot 0 --output_path ./base
curl -X POST http://localhost:8001/v1/load_lora_adapter -H "Content-Type: application/json" -d '{"lora_name": "adapter", "lora_path": "/home/densemax2/work/flavius/surogate/output/benchmark_sft_qfp8/adapter"}'
curl -X POST http://localhost:8001/v1/unload_lora_adapter -H "Content-Type: application/json" -d '{"lora_name": "adapter"}'